Vyzkoušejte AI na VAŠEM webu za 60 sekund
Podívejte se, jak naše AI okamžitě analyzuje váš web a vytvoří personalizovaného chatbota - bez registrace. Stačí zadat URL adresu a sledovat, jak to funguje!
Připraveno za 60 sekund
Není potřeba programování
100% bezpečné
Skromné začátky: Rané systémy založené na pravidlech
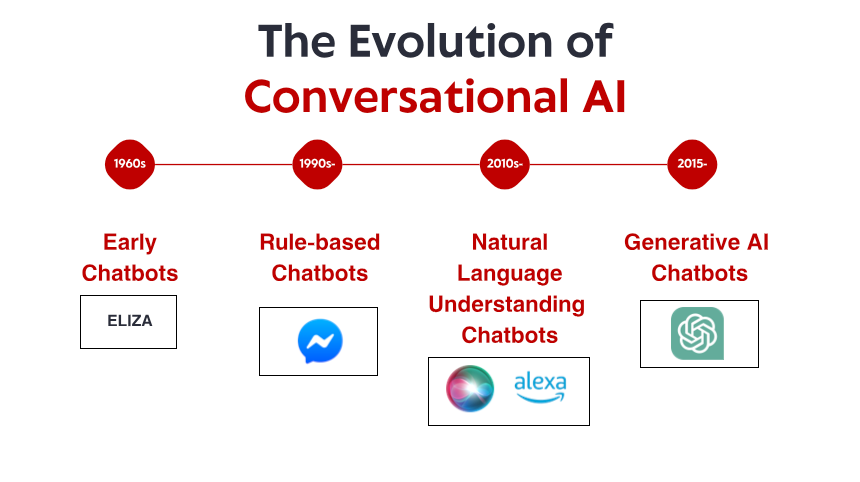
Příběh konverzační umělé inteligence začíná v 60. letech 20. století, dlouho předtím, než se chytré telefony a hlasoví asistenti stali běžnou součástí domácností. V malé laboratoři na MIT vytvořil počítačový vědec Joseph Weizenbaum to, co mnozí považují za prvního chatbota: ELIZA. ELIZA, navržená tak, aby simulovala rogeriánského psychoterapeuta, pracovala na jednoduchých pravidlech porovnávání vzorů a substituce. Když uživatel zadá „Je mi smutno“, ELIZA mohla odpovědět „Proč se cítíš smutný?“ – vytváření iluze porozumění přeformulováním výroků na otázky.
To, co dělalo ELIZA pozoruhodnou, nebyla její technická vyspělost – na dnešní poměry byl program neuvěřitelně základní. Spíše to byl hluboký účinek, který to mělo na uživatele. Přestože věděli, že mluví s počítačovým programem bez skutečného porozumění, mnoho lidí si vytvořilo emocionální spojení s ELIZOU a sdíleli hluboce osobní myšlenky a pocity. Tento fenomén, který sám Weizenbaum považoval za znepokojivý, odhalil něco zásadního o lidské psychologii a naší ochotě antropomorfizovat i ta nejjednodušší konverzační rozhraní.
Během 70. a 80. let 20. století chatboti na základě pravidel následovali šablonu ELIZA s postupnými vylepšeními. Programy jako PARRY (simulující paranoidního schizofrenika) a RACTER (který „napsal“ knihu nazvanou „Policajtovy vousy jsou napůl vytvořené“) zůstaly pevně v paradigmatu založeném na pravidlech – využívající předdefinované vzory, shodu klíčových slov a šablonované odpovědi.
Tyto rané systémy měly vážná omezení. Nemohli ve skutečnosti rozumět jazyku, učit se z interakcí nebo se přizpůsobit neočekávaným vstupům. Jejich znalosti byly omezeny na jakákoli pravidla, která jejich programátoři výslovně definovali. Když se uživatelé nevyhnutelně dostali mimo tyto hranice, iluze inteligence se rychle rozbila a odhalila mechanickou povahu pod nimi. Navzdory těmto omezením tyto průkopnické systémy vytvořily základ, na kterém bude stavět veškerá budoucí konverzační umělá inteligence.
To, co dělalo ELIZA pozoruhodnou, nebyla její technická vyspělost – na dnešní poměry byl program neuvěřitelně základní. Spíše to byl hluboký účinek, který to mělo na uživatele. Přestože věděli, že mluví s počítačovým programem bez skutečného porozumění, mnoho lidí si vytvořilo emocionální spojení s ELIZOU a sdíleli hluboce osobní myšlenky a pocity. Tento fenomén, který sám Weizenbaum považoval za znepokojivý, odhalil něco zásadního o lidské psychologii a naší ochotě antropomorfizovat i ta nejjednodušší konverzační rozhraní.
Během 70. a 80. let 20. století chatboti na základě pravidel následovali šablonu ELIZA s postupnými vylepšeními. Programy jako PARRY (simulující paranoidního schizofrenika) a RACTER (který „napsal“ knihu nazvanou „Policajtovy vousy jsou napůl vytvořené“) zůstaly pevně v paradigmatu založeném na pravidlech – využívající předdefinované vzory, shodu klíčových slov a šablonované odpovědi.
Tyto rané systémy měly vážná omezení. Nemohli ve skutečnosti rozumět jazyku, učit se z interakcí nebo se přizpůsobit neočekávaným vstupům. Jejich znalosti byly omezeny na jakákoli pravidla, která jejich programátoři výslovně definovali. Když se uživatelé nevyhnutelně dostali mimo tyto hranice, iluze inteligence se rychle rozbila a odhalila mechanickou povahu pod nimi. Navzdory těmto omezením tyto průkopnické systémy vytvořily základ, na kterém bude stavět veškerá budoucí konverzační umělá inteligence.
Revoluce znalostí: Expertní systémy a strukturované informace
V 80. a na počátku 90. let 20. století došlo k vzestupu expertních systémů – programů AI navržených k řešení složitých problémů napodobováním rozhodovacích schopností lidských expertů ve specifických oblastech. I když tyto systémy nebyly primárně určeny pro konverzaci, představovaly důležitý evoluční krok pro konverzační AI zavedením sofistikovanější reprezentace znalostí.
Expertní systémy jako MYCIN (který diagnostikoval bakteriální infekce) a DENDRAL (který identifikoval chemické sloučeniny) organizovaly informace do strukturovaných znalostních bází a k vyvozování závěrů používaly inferenční motory. Když byl tento přístup aplikován na konverzační rozhraní, umožnil chatbotům přejít od jednoduchého porovnávání vzorů směrem k něčemu podobnému uvažování – alespoň v rámci úzkých domén.
Společnosti začaly implementovat praktické aplikace, jako jsou automatizované systémy zákaznických služeb využívající tuto technologii. Tyto systémy obvykle používaly rozhodovací stromy a interakce založené na nabídkách spíše než volnou konverzaci, ale představovaly rané pokusy o automatizaci interakcí, které dříve vyžadovaly lidský zásah.
Omezení zůstala významná. Tyto systémy byly křehké, nebyly schopny elegantně zvládnout neočekávané vstupy. Od znalostních inženýrů vyžadovaly obrovské úsilí, aby ručně zakódovali informace a pravidla. A co je možná nejdůležitější, stále nedokázali skutečně pochopit přirozený jazyk v jeho plné složitosti a nejednoznačnosti.
Nicméně tato éra vytvořila důležité koncepty, které se později staly zásadními pro moderní konverzační AI: strukturovaná reprezentace znalostí, logické vyvozování a doménová specializace. Pódium se připravovalo pro změnu paradigmatu, i když technologie ještě nebyla úplně tam.
Expertní systémy jako MYCIN (který diagnostikoval bakteriální infekce) a DENDRAL (který identifikoval chemické sloučeniny) organizovaly informace do strukturovaných znalostních bází a k vyvozování závěrů používaly inferenční motory. Když byl tento přístup aplikován na konverzační rozhraní, umožnil chatbotům přejít od jednoduchého porovnávání vzorů směrem k něčemu podobnému uvažování – alespoň v rámci úzkých domén.
Společnosti začaly implementovat praktické aplikace, jako jsou automatizované systémy zákaznických služeb využívající tuto technologii. Tyto systémy obvykle používaly rozhodovací stromy a interakce založené na nabídkách spíše než volnou konverzaci, ale představovaly rané pokusy o automatizaci interakcí, které dříve vyžadovaly lidský zásah.
Omezení zůstala významná. Tyto systémy byly křehké, nebyly schopny elegantně zvládnout neočekávané vstupy. Od znalostních inženýrů vyžadovaly obrovské úsilí, aby ručně zakódovali informace a pravidla. A co je možná nejdůležitější, stále nedokázali skutečně pochopit přirozený jazyk v jeho plné složitosti a nejednoznačnosti.
Nicméně tato éra vytvořila důležité koncepty, které se později staly zásadními pro moderní konverzační AI: strukturovaná reprezentace znalostí, logické vyvozování a doménová specializace. Pódium se připravovalo pro změnu paradigmatu, i když technologie ještě nebyla úplně tam.
Pochopení přirozeného jazyka: Průlom ve výpočetní lingvistice
Konec 90. let a počátek 21. století přinesl rostoucí zaměření na zpracování přirozeného jazyka (NLP) a počítačovou lingvistiku. Spíše než se snažit ručně kódovat pravidla pro každou možnou interakci, začali výzkumníci vyvíjet statistické metody, které mají počítačům pomoci porozumět přirozeným vzorcům lidské řeči.
Tento posun byl umožněn několika faktory: zvýšením výpočetního výkonu, lepšími algoritmy a především dostupností velkých textových korpusů, které by bylo možné analyzovat k identifikaci jazykových vzorů. Systémy začaly zahrnovat techniky jako:
Part-of-speech taging: Identifikace, zda slova fungovala jako podstatná jména, slovesa, přídavná jména atd.
Rozpoznávání pojmenovaných entit: Detekce a klasifikace vlastních jmen (osob, organizací, míst).
Analýza sentimentu: Určení emocionálního vyznění textu.
Analýza: Analýza větné struktury k identifikaci gramatických vztahů mezi slovy.
Jeden pozoruhodný průlom přišel s Watsonem od IBM, který skvěle porazil lidské šampióny v kvízu Jeopardy! v roce 2011. I když se nejednalo o striktně konverzační systém, Watson prokázal bezprecedentní schopnosti porozumět otázkám přirozeného jazyka, prohledávat rozsáhlé úložiště znalostí a formulovat odpovědi – schopnosti, které by se ukázaly jako zásadní pro příští generaci chatbotů.
Komerční aplikace brzy následovaly. Apple Siri byl uveden na trh v roce 2011 a přinesl konverzační rozhraní běžným spotřebitelům. Přestože je Siri omezena dnešními standardy, představovala významný pokrok ve zpřístupňování asistentů AI každodenním uživatelům. Cortana od Microsoftu, asistent od Googlu a Alexa od Amazonu budou následovat, přičemž oba posouvají kupředu nejmodernější konverzační AI pro spotřebitele.
Navzdory těmto pokrokům se systémy z této éry stále potýkaly s kontextem, zdravým rozumem a generováním skutečně přirozeně znějících odpovědí. Byli důmyslnější než jejich prapředkové, ale zůstali zásadně omezeni v chápání jazyka a světa.
Tento posun byl umožněn několika faktory: zvýšením výpočetního výkonu, lepšími algoritmy a především dostupností velkých textových korpusů, které by bylo možné analyzovat k identifikaci jazykových vzorů. Systémy začaly zahrnovat techniky jako:
Part-of-speech taging: Identifikace, zda slova fungovala jako podstatná jména, slovesa, přídavná jména atd.
Rozpoznávání pojmenovaných entit: Detekce a klasifikace vlastních jmen (osob, organizací, míst).
Analýza sentimentu: Určení emocionálního vyznění textu.
Analýza: Analýza větné struktury k identifikaci gramatických vztahů mezi slovy.
Jeden pozoruhodný průlom přišel s Watsonem od IBM, který skvěle porazil lidské šampióny v kvízu Jeopardy! v roce 2011. I když se nejednalo o striktně konverzační systém, Watson prokázal bezprecedentní schopnosti porozumět otázkám přirozeného jazyka, prohledávat rozsáhlé úložiště znalostí a formulovat odpovědi – schopnosti, které by se ukázaly jako zásadní pro příští generaci chatbotů.
Komerční aplikace brzy následovaly. Apple Siri byl uveden na trh v roce 2011 a přinesl konverzační rozhraní běžným spotřebitelům. Přestože je Siri omezena dnešními standardy, představovala významný pokrok ve zpřístupňování asistentů AI každodenním uživatelům. Cortana od Microsoftu, asistent od Googlu a Alexa od Amazonu budou následovat, přičemž oba posouvají kupředu nejmodernější konverzační AI pro spotřebitele.
Navzdory těmto pokrokům se systémy z této éry stále potýkaly s kontextem, zdravým rozumem a generováním skutečně přirozeně znějících odpovědí. Byli důmyslnější než jejich prapředkové, ale zůstali zásadně omezeni v chápání jazyka a světa.
Strojové učení a přístup založený na datech
Polovina roku 2010 znamenala další změnu paradigmatu v konverzační umělé inteligenci s běžným přijetím technik strojového učení. Namísto spoléhání se na ručně vytvořená pravidla nebo omezené statistické modely začali inženýři budovat systémy, které by se mohly učit vzorce přímo z dat – a hodně z nich.
Tato éra zaznamenala vzestup klasifikace záměrů a extrakce entit jako klíčových součástí konverzační architektury. Když uživatel zadá požadavek, systém:
Klasifikujte celkový záměr (např. rezervace letu, kontrola počasí, přehrávání hudby)
Extrahujte relevantní entity (např. místa, data, názvy skladeb)
Mapujte je na konkrétní akce nebo reakce
Spuštění platformy Messenger od Facebooku (nyní Meta) v roce 2016 umožnilo vývojářům vytvářet chatboty, které by mohly oslovit miliony uživatelů, což vyvolalo vlnu komerčního zájmu. Mnoho společností spěchalo s implementací chatbotů, ačkoli výsledky byly smíšené. Rané komerční implementace často frustrovaly uživatele omezeným porozuměním a strnulými konverzačními toky.
V tomto období se také vyvíjela technická architektura konverzačních systémů. Typický přístup zahrnoval řadu specializovaných komponent:
Automatické rozpoznávání řeči (pro hlasová rozhraní)
Pochopení přirozeného jazyka
Správa dialogů
Generování přirozeného jazyka
Převod textu na řeč (pro hlasová rozhraní)
Každá komponenta může být optimalizována samostatně, což umožňuje postupná vylepšení. Tyto potrubní architektury však někdy trpěly šířením chyb – chyby v raných fázích by kaskádově procházely systémem.
Zatímco strojové učení výrazně zlepšilo možnosti, systémy se stále potýkaly s udržováním kontextu během dlouhých konverzací, porozuměním implicitním informacím a generováním skutečně různorodých a přirozených reakcí. Další průlom by vyžadoval radikálnější přístup.
Tato éra zaznamenala vzestup klasifikace záměrů a extrakce entit jako klíčových součástí konverzační architektury. Když uživatel zadá požadavek, systém:
Klasifikujte celkový záměr (např. rezervace letu, kontrola počasí, přehrávání hudby)
Extrahujte relevantní entity (např. místa, data, názvy skladeb)
Mapujte je na konkrétní akce nebo reakce
Spuštění platformy Messenger od Facebooku (nyní Meta) v roce 2016 umožnilo vývojářům vytvářet chatboty, které by mohly oslovit miliony uživatelů, což vyvolalo vlnu komerčního zájmu. Mnoho společností spěchalo s implementací chatbotů, ačkoli výsledky byly smíšené. Rané komerční implementace často frustrovaly uživatele omezeným porozuměním a strnulými konverzačními toky.
V tomto období se také vyvíjela technická architektura konverzačních systémů. Typický přístup zahrnoval řadu specializovaných komponent:
Automatické rozpoznávání řeči (pro hlasová rozhraní)
Pochopení přirozeného jazyka
Správa dialogů
Generování přirozeného jazyka
Převod textu na řeč (pro hlasová rozhraní)
Každá komponenta může být optimalizována samostatně, což umožňuje postupná vylepšení. Tyto potrubní architektury však někdy trpěly šířením chyb – chyby v raných fázích by kaskádově procházely systémem.
Zatímco strojové učení výrazně zlepšilo možnosti, systémy se stále potýkaly s udržováním kontextu během dlouhých konverzací, porozuměním implicitním informacím a generováním skutečně různorodých a přirozených reakcí. Další průlom by vyžadoval radikálnější přístup.
Transformátorová revoluce: Modely neuronových jazyků
Rok 2017 znamenal přelomový okamžik v historii umělé inteligence vydáním publikace „Attention Is All You Need“, která představila architekturu Transformer, která by způsobila revoluci ve zpracování přirozeného jazyka. Na rozdíl od předchozích přístupů, které zpracovávaly text postupně, mohli Transformers zvažovat celou pasáž současně, což jim umožnilo lépe zachytit vztahy mezi slovy bez ohledu na jejich vzájemnou vzdálenost.
Tato inovace umožnila vývoj stále výkonnějších jazykových modelů. V roce 2018 Google představil BERT (obousměrné kodérové reprezentace od Transformers), který dramaticky zlepšil výkon při různých úlohách porozumění jazyku. V roce 2019 vydala OpenAI GPT-2, která prokázala bezprecedentní schopnosti při generování koherentního, kontextově relevantního textu.
Nejdramatičtější skok přišel v roce 2020 s GPT-3, škálováním až na 175 miliard parametrů (ve srovnání s 1,5 miliardami GPT-2). Toto masivní zvětšení měřítka v kombinaci s architektonickými vylepšeními přineslo kvalitativně odlišné schopnosti. GPT-3 dokázalo generovat pozoruhodně lidský text, porozumět kontextu v tisících slov a dokonce provádět úkoly, na které nebyl výslovně vyškolen.
U konverzační umělé inteligence se tyto pokroky přenesly na chatboty, které by mohly:
Udržujte souvislé konverzace v mnoha kolech
Pochopte jemné dotazy bez explicitního školení
Vytvářejte různorodé, kontextuálně vhodné odpovědi
Přizpůsobte jejich tón a styl tak, aby odpovídaly uživateli
Vyřešte nejasnosti a v případě potřeby vyjasněte
Vydání ChatGPT na konci roku 2022 přineslo tyto funkce do hlavního proudu a přilákalo více než milion uživatelů během několika dní od svého spuštění. Najednou měla široká veřejnost přístup ke konverzační umělé inteligenci, která se zdála být kvalitativně odlišná od všeho, co bylo předtím – flexibilnější, informovanější a přirozenější ve svých interakcích.
Komerční implementace rychle následovaly a společnosti začlenily velké jazykové modely do svých platforem zákaznických služeb, nástrojů pro tvorbu obsahu a aplikací pro zvýšení produktivity. Rychlé přijetí odráželo technologický skok i intuitivní rozhraní, které tyto modely poskytovaly – konverzace je koneckonců pro lidi nejpřirozenější způsob komunikace.
Tato inovace umožnila vývoj stále výkonnějších jazykových modelů. V roce 2018 Google představil BERT (obousměrné kodérové reprezentace od Transformers), který dramaticky zlepšil výkon při různých úlohách porozumění jazyku. V roce 2019 vydala OpenAI GPT-2, která prokázala bezprecedentní schopnosti při generování koherentního, kontextově relevantního textu.
Nejdramatičtější skok přišel v roce 2020 s GPT-3, škálováním až na 175 miliard parametrů (ve srovnání s 1,5 miliardami GPT-2). Toto masivní zvětšení měřítka v kombinaci s architektonickými vylepšeními přineslo kvalitativně odlišné schopnosti. GPT-3 dokázalo generovat pozoruhodně lidský text, porozumět kontextu v tisících slov a dokonce provádět úkoly, na které nebyl výslovně vyškolen.
U konverzační umělé inteligence se tyto pokroky přenesly na chatboty, které by mohly:
Udržujte souvislé konverzace v mnoha kolech
Pochopte jemné dotazy bez explicitního školení
Vytvářejte různorodé, kontextuálně vhodné odpovědi
Přizpůsobte jejich tón a styl tak, aby odpovídaly uživateli
Vyřešte nejasnosti a v případě potřeby vyjasněte
Vydání ChatGPT na konci roku 2022 přineslo tyto funkce do hlavního proudu a přilákalo více než milion uživatelů během několika dní od svého spuštění. Najednou měla široká veřejnost přístup ke konverzační umělé inteligenci, která se zdála být kvalitativně odlišná od všeho, co bylo předtím – flexibilnější, informovanější a přirozenější ve svých interakcích.
Komerční implementace rychle následovaly a společnosti začlenily velké jazykové modely do svých platforem zákaznických služeb, nástrojů pro tvorbu obsahu a aplikací pro zvýšení produktivity. Rychlé přijetí odráželo technologický skok i intuitivní rozhraní, které tyto modely poskytovaly – konverzace je koneckonců pro lidi nejpřirozenější způsob komunikace.
Vyzkoušejte AI na VAŠEM webu za 60 sekund
Podívejte se, jak naše AI okamžitě analyzuje váš web a vytvoří personalizovaného chatbota - bez registrace. Stačí zadat URL adresu a sledovat, jak to funguje!
Připraveno za 60 sekund
Není potřeba programování
100% bezpečné
Multimodální schopnosti: Mimo pouze textové konverzace
Zatímco ve vývoji konverzační umělé inteligence dominuje text, v posledních letech došlo k posunu směrem k multimodálním systémům, které dokážou porozumět a generovat více typů médií. Tento vývoj odráží základní pravdu o lidské komunikaci – nepoužíváme jen slova; gestikulujeme, ukazujeme obrázky, kreslíme diagramy a využíváme své prostředí k vyjádření významu.
Modely v jazyce vidění jako DALL-E, Midjourney a Stable Diffusion prokázaly schopnost generovat obrázky z textových popisů, zatímco modely jako GPT-4 s schopnostmi vidění mohly analyzovat obrázky a inteligentně o nich diskutovat. To otevřelo nové možnosti pro konverzační rozhraní:
Roboti zákaznického servisu, kteří mohou analyzovat fotografie poškozených produktů
Nákupní asistenti, kteří dokážou identifikovat položky z obrázků a najít podobné produkty
Vzdělávací nástroje, které mohou vysvětlit diagramy a vizuální koncepty
Funkce usnadnění, které mohou popisovat obrázky pro zrakově postižené uživatele
Výrazně pokročily také hlasové schopnosti. Raná hlasová rozhraní, jako jsou systémy IVR (Interactive Voice Response), byly notoricky frustrující, omezené na rigidní příkazy a struktury menu. Moderní hlasoví asistenti dokážou porozumět přirozeným řečovým vzorům, zohlednit různé přízvuky a řečové vady a reagovat stále přirozeněji znějícími syntetizovanými hlasy.
Spojení těchto schopností vytváří skutečně multimodální konverzační umělou inteligenci, která dokáže plynule přepínat mezi různými komunikačními režimy na základě kontextu a potřeb uživatelů. Uživatel může začít textovou otázkou o opravě tiskárny, odeslat fotografii chybové zprávy, obdržet schéma zvýrazňující příslušná tlačítka a poté přepnout na hlasové pokyny, zatímco má ruce zaneprázdněné opravou.
Tento multimodální přístup představuje nejen technický pokrok, ale zásadní posun směrem k přirozenější interakci člověk-počítač – setkávání uživatelů v jakémkoli komunikačním režimu, který nejlépe vyhovuje jejich aktuálnímu kontextu a potřebám.
Modely v jazyce vidění jako DALL-E, Midjourney a Stable Diffusion prokázaly schopnost generovat obrázky z textových popisů, zatímco modely jako GPT-4 s schopnostmi vidění mohly analyzovat obrázky a inteligentně o nich diskutovat. To otevřelo nové možnosti pro konverzační rozhraní:
Roboti zákaznického servisu, kteří mohou analyzovat fotografie poškozených produktů
Nákupní asistenti, kteří dokážou identifikovat položky z obrázků a najít podobné produkty
Vzdělávací nástroje, které mohou vysvětlit diagramy a vizuální koncepty
Funkce usnadnění, které mohou popisovat obrázky pro zrakově postižené uživatele
Výrazně pokročily také hlasové schopnosti. Raná hlasová rozhraní, jako jsou systémy IVR (Interactive Voice Response), byly notoricky frustrující, omezené na rigidní příkazy a struktury menu. Moderní hlasoví asistenti dokážou porozumět přirozeným řečovým vzorům, zohlednit různé přízvuky a řečové vady a reagovat stále přirozeněji znějícími syntetizovanými hlasy.
Spojení těchto schopností vytváří skutečně multimodální konverzační umělou inteligenci, která dokáže plynule přepínat mezi různými komunikačními režimy na základě kontextu a potřeb uživatelů. Uživatel může začít textovou otázkou o opravě tiskárny, odeslat fotografii chybové zprávy, obdržet schéma zvýrazňující příslušná tlačítka a poté přepnout na hlasové pokyny, zatímco má ruce zaneprázdněné opravou.
Tento multimodální přístup představuje nejen technický pokrok, ale zásadní posun směrem k přirozenější interakci člověk-počítač – setkávání uživatelů v jakémkoli komunikačním režimu, který nejlépe vyhovuje jejich aktuálnímu kontextu a potřebám.
Generace s rozšířeným získáváním: Uzemnění umělé inteligence ve faktech
Navzdory svým působivým schopnostem mají velké jazykové modely vlastní omezení. Mohou „halucinovat“ informace, sebevědomě uvádějí věrohodně znějící, ale nesprávná fakta. Jejich znalosti jsou omezeny na to, co bylo v jejich tréninkových datech, což vytváří datum pro ukončení znalostí. A chybí jim možnost přístupu k informacím v reálném čase nebo specializovaným databázím, pokud k tomu nejsou speciálně navrženy.
Retrieval-Augmented Generation (RAG) se objevila jako řešení těchto problémů. Spíše než se spoléhat pouze na parametry získané během školení, systémy RAG kombinují generativní schopnosti jazykových modelů s mechanismy vyhledávání, které mohou přistupovat k externím zdrojům znalostí.
Typická architektura RAG funguje takto:
Systém obdrží uživatelský dotaz
Vyhledává v relevantních znalostních bázích informace související s dotazem
Do jazykového modelu dodává jak dotaz, tak načtené informace
Model generuje odpověď založenou na získaných faktech
Tento přístup nabízí několik výhod:
Přesnější, faktické odpovědi díky generování uzemnění v ověřených informacích
Schopnost přístupu k aktuálním informacím za hranicemi tréninkového období modelu
Specializované znalosti z doménově specifických zdrojů, jako je firemní dokumentace
Transparentnost a připisování uvedením zdrojů informací
Pro podniky, které implementují konverzační umělou inteligenci, se RAG ukázal jako zvláště cenný pro aplikace zákaznických služeb. Bankovní chatbot má například přístup k nejnovějším dokumentům zásad, informacím o účtu a záznamům transakcí, aby mohl poskytovat přesné, personalizované odpovědi, které by se samostatným jazykovým modelem nebyly možné.
Vývoj systémů RAG pokračuje zlepšením přesnosti vyhledávání, sofistikovanějšími metodami pro integraci získaných informací s generovaným textem a lepšími mechanismy pro hodnocení spolehlivosti různých informačních zdrojů.
Retrieval-Augmented Generation (RAG) se objevila jako řešení těchto problémů. Spíše než se spoléhat pouze na parametry získané během školení, systémy RAG kombinují generativní schopnosti jazykových modelů s mechanismy vyhledávání, které mohou přistupovat k externím zdrojům znalostí.
Typická architektura RAG funguje takto:
Systém obdrží uživatelský dotaz
Vyhledává v relevantních znalostních bázích informace související s dotazem
Do jazykového modelu dodává jak dotaz, tak načtené informace
Model generuje odpověď založenou na získaných faktech
Tento přístup nabízí několik výhod:
Přesnější, faktické odpovědi díky generování uzemnění v ověřených informacích
Schopnost přístupu k aktuálním informacím za hranicemi tréninkového období modelu
Specializované znalosti z doménově specifických zdrojů, jako je firemní dokumentace
Transparentnost a připisování uvedením zdrojů informací
Pro podniky, které implementují konverzační umělou inteligenci, se RAG ukázal jako zvláště cenný pro aplikace zákaznických služeb. Bankovní chatbot má například přístup k nejnovějším dokumentům zásad, informacím o účtu a záznamům transakcí, aby mohl poskytovat přesné, personalizované odpovědi, které by se samostatným jazykovým modelem nebyly možné.
Vývoj systémů RAG pokračuje zlepšením přesnosti vyhledávání, sofistikovanějšími metodami pro integraci získaných informací s generovaným textem a lepšími mechanismy pro hodnocení spolehlivosti různých informačních zdrojů.
Model spolupráce člověka a umělé inteligence: Nalezení správné rovnováhy
S rozšiřováním schopností konverzační umělé inteligence se vyvíjel i vztah mezi lidmi a systémy umělé inteligence. První chatboti byli jasně umístěni jako nástroje – omezený rozsahem a zjevně nelidské ve svých interakcích. Moderní systémy tyto linie rozmazávají a vytvářejí nové otázky, jak navrhnout efektivní spolupráci člověka a umělé inteligence.
Nejúspěšnější implementace se dnes řídí modelem spolupráce, kde:
AI zpracovává rutinní, opakující se dotazy, které nevyžadují lidský úsudek
Lidé se zaměřují na složité případy vyžadující empatii, etické uvažování nebo kreativní řešení problémů
Systém zná svá omezení a v případě potřeby plynule eskaluje k lidským agentům
Přechod mezi AI a lidskou podporou je pro uživatele bezproblémový
Lidští agenti mají úplný kontext historie konverzace s AI
Umělá inteligence se nadále učí z lidských zásahů a postupně rozšiřuje své schopnosti
Tento přístup uznává, že konverzační umělá inteligence by neměla mít za cíl zcela nahradit lidskou interakci, ale spíše ji doplňovat – zpracovávat velké objemy, přímočaré dotazy, které spotřebovávají čas lidských agentů, a zároveň zajistit, aby se složité problémy dostaly ke správné lidské expertíze.
Implementace tohoto modelu se v různých odvětvích liší. Ve zdravotnictví mohou chatboti s umělou inteligencí zvládnout plánování schůzek a základní screening symptomů a zároveň zajistit, aby lékařská rada pocházela od kvalifikovaných odborníků. V právních službách může umělá inteligence pomoci s přípravou dokumentů a výzkumem, přičemž výklad a strategii ponechává na právnících. V zákaznických službách dokáže umělá inteligence vyřešit běžné problémy a zároveň směrovat složité problémy ke specializovaným agentům.
Jak se schopnosti umělé inteligence neustále rozšiřují, hranice mezi tím, co vyžaduje zapojení člověka a tím, co lze automatizovat, se bude posouvat, ale základní princip zůstává: efektivní konverzační umělá inteligence by měla lidské schopnosti spíše posilovat, než je jednoduše nahrazovat.
Nejúspěšnější implementace se dnes řídí modelem spolupráce, kde:
AI zpracovává rutinní, opakující se dotazy, které nevyžadují lidský úsudek
Lidé se zaměřují na složité případy vyžadující empatii, etické uvažování nebo kreativní řešení problémů
Systém zná svá omezení a v případě potřeby plynule eskaluje k lidským agentům
Přechod mezi AI a lidskou podporou je pro uživatele bezproblémový
Lidští agenti mají úplný kontext historie konverzace s AI
Umělá inteligence se nadále učí z lidských zásahů a postupně rozšiřuje své schopnosti
Tento přístup uznává, že konverzační umělá inteligence by neměla mít za cíl zcela nahradit lidskou interakci, ale spíše ji doplňovat – zpracovávat velké objemy, přímočaré dotazy, které spotřebovávají čas lidských agentů, a zároveň zajistit, aby se složité problémy dostaly ke správné lidské expertíze.
Implementace tohoto modelu se v různých odvětvích liší. Ve zdravotnictví mohou chatboti s umělou inteligencí zvládnout plánování schůzek a základní screening symptomů a zároveň zajistit, aby lékařská rada pocházela od kvalifikovaných odborníků. V právních službách může umělá inteligence pomoci s přípravou dokumentů a výzkumem, přičemž výklad a strategii ponechává na právnících. V zákaznických službách dokáže umělá inteligence vyřešit běžné problémy a zároveň směrovat složité problémy ke specializovaným agentům.
Jak se schopnosti umělé inteligence neustále rozšiřují, hranice mezi tím, co vyžaduje zapojení člověka a tím, co lze automatizovat, se bude posouvat, ale základní princip zůstává: efektivní konverzační umělá inteligence by měla lidské schopnosti spíše posilovat, než je jednoduše nahrazovat.
Krajina budoucnosti: Kam směřuje konverzační umělá inteligence
Když se podíváme na horizont, budoucnost konverzační umělé inteligence utváří několik nových trendů. Tento vývoj slibuje nejen postupná zlepšení, ale také potenciálně transformační změny v tom, jak interagujeme s technologií.
Personalizace ve velkém: Budoucí systémy budou stále více přizpůsobovat své reakce nejen bezprostřednímu kontextu, ale také komunikačnímu stylu každého uživatele, preferencím, úrovni znalostí a historii vztahů. Díky této personalizaci budou interakce přirozenější a relevantnější, ačkoli vyvolává důležité otázky týkající se soukromí a využití dat.
Emoční inteligence: Zatímco dnešní systémy dokážou detekovat základní sentiment, budoucí konverzační umělá inteligence vyvine sofistikovanější emoční inteligenci – rozpozná jemné emoční stavy, vhodně reaguje na úzkost nebo frustraci a podle toho přizpůsobí svůj tón a přístup. Tato schopnost bude zvláště cenná v aplikacích zákaznických služeb, zdravotnictví a vzdělávání.
Proaktivní pomoc: Namísto čekání na explicitní dotazy budou konverzační systémy nové generace předvídat potřeby na základě kontextu, uživatelské historie a signálů prostředí. Systém si může všimnout, že plánujete několik schůzek v neznámém městě, a proaktivně nabídnout možnosti dopravy nebo předpověď počasí.
Bezproblémová multimodální integrace: Budoucí systémy se posunou od pouhé podpory různých modalit k jejich bezproblémové integraci. Konverzace může přirozeně plynout mezi textem, hlasem, obrázky a interaktivními prvky a vybrat správnou modalitu pro každou informaci, aniž by byl vyžadován explicitní výběr uživatele.
Specializovaní experti na doménu: I když se asistenti pro všeobecné použití budou nadále zlepšovat, uvidíme také vzestup vysoce specializované konverzační umělé inteligence s hlubokými odbornými znalostmi ve specifických oblastech – právní asistenti, kteří rozumí judikatuře a precedentům, lékařské systémy s komplexní znalostí lékových interakcí a léčebných protokolů nebo finanční poradci zběhlí v daňových zákonících a investičních strategiích.
Skutečně nepřetržité učení: Budoucí systémy se posunou od pravidelného přeškolování k nepřetržitému učení z interakcí, které se postupem času stanou užitečnějšími a personalizovanými při zachování vhodných záruk ochrany soukromí.
Navzdory těmto vzrušujícím možnostem zůstávají výzvy. Obavy o soukromí, zmírňování předsudků, vhodná transparentnost a stanovení správné úrovně lidského dohledu jsou přetrvávající problémy, které budou formovat technologii i její regulaci. Nejúspěšnější implementace budou ty, které tyto výzvy řeší promyšleně a zároveň uživatelům přinášejí skutečnou hodnotu.
Jasné je, že konverzační umělá inteligence se posunula od specializované technologie k běžnému paradigmatu rozhraní, které bude stále více zprostředkovávat naše interakce s digitálními systémy. Evoluční cesta od jednoduchého porovnávání vzorů ELIZA k dnešním sofistikovaným jazykovým modelům představuje jeden z nejvýznamnějších pokroků v interakci mezi člověkem a počítačem – a tato cesta zdaleka nekončí.
Personalizace ve velkém: Budoucí systémy budou stále více přizpůsobovat své reakce nejen bezprostřednímu kontextu, ale také komunikačnímu stylu každého uživatele, preferencím, úrovni znalostí a historii vztahů. Díky této personalizaci budou interakce přirozenější a relevantnější, ačkoli vyvolává důležité otázky týkající se soukromí a využití dat.
Emoční inteligence: Zatímco dnešní systémy dokážou detekovat základní sentiment, budoucí konverzační umělá inteligence vyvine sofistikovanější emoční inteligenci – rozpozná jemné emoční stavy, vhodně reaguje na úzkost nebo frustraci a podle toho přizpůsobí svůj tón a přístup. Tato schopnost bude zvláště cenná v aplikacích zákaznických služeb, zdravotnictví a vzdělávání.
Proaktivní pomoc: Namísto čekání na explicitní dotazy budou konverzační systémy nové generace předvídat potřeby na základě kontextu, uživatelské historie a signálů prostředí. Systém si může všimnout, že plánujete několik schůzek v neznámém městě, a proaktivně nabídnout možnosti dopravy nebo předpověď počasí.
Bezproblémová multimodální integrace: Budoucí systémy se posunou od pouhé podpory různých modalit k jejich bezproblémové integraci. Konverzace může přirozeně plynout mezi textem, hlasem, obrázky a interaktivními prvky a vybrat správnou modalitu pro každou informaci, aniž by byl vyžadován explicitní výběr uživatele.
Specializovaní experti na doménu: I když se asistenti pro všeobecné použití budou nadále zlepšovat, uvidíme také vzestup vysoce specializované konverzační umělé inteligence s hlubokými odbornými znalostmi ve specifických oblastech – právní asistenti, kteří rozumí judikatuře a precedentům, lékařské systémy s komplexní znalostí lékových interakcí a léčebných protokolů nebo finanční poradci zběhlí v daňových zákonících a investičních strategiích.
Skutečně nepřetržité učení: Budoucí systémy se posunou od pravidelného přeškolování k nepřetržitému učení z interakcí, které se postupem času stanou užitečnějšími a personalizovanými při zachování vhodných záruk ochrany soukromí.
Navzdory těmto vzrušujícím možnostem zůstávají výzvy. Obavy o soukromí, zmírňování předsudků, vhodná transparentnost a stanovení správné úrovně lidského dohledu jsou přetrvávající problémy, které budou formovat technologii i její regulaci. Nejúspěšnější implementace budou ty, které tyto výzvy řeší promyšleně a zároveň uživatelům přinášejí skutečnou hodnotu.
Jasné je, že konverzační umělá inteligence se posunula od specializované technologie k běžnému paradigmatu rozhraní, které bude stále více zprostředkovávat naše interakce s digitálními systémy. Evoluční cesta od jednoduchého porovnávání vzorů ELIZA k dnešním sofistikovaným jazykovým modelům představuje jeden z nejvýznamnějších pokroků v interakci mezi člověkem a počítačem – a tato cesta zdaleka nekončí.





